Issues: Cold start problems and High labeling efforts in log-based anomaly
detection
On one hand, during the initial deployment phase of software systems, it is impossible to
accumulate sufficient logs to train an effective anomaly detection model. On the other hand, the
massive and complex log data is difficult to accurately label, requiring substantial labeling
costs.
Key technologies: Incorporate Active learning and
Transfer learning
Transfer learning is employed to address the cold-start problem, LogAction training models on
mature systems and transferring them to new systems with insufficient data accumulation.
Meanwhile, active learning is utilized to reduce the amount of labels required during model
transfer process, thereby lowering manual labeling costs.
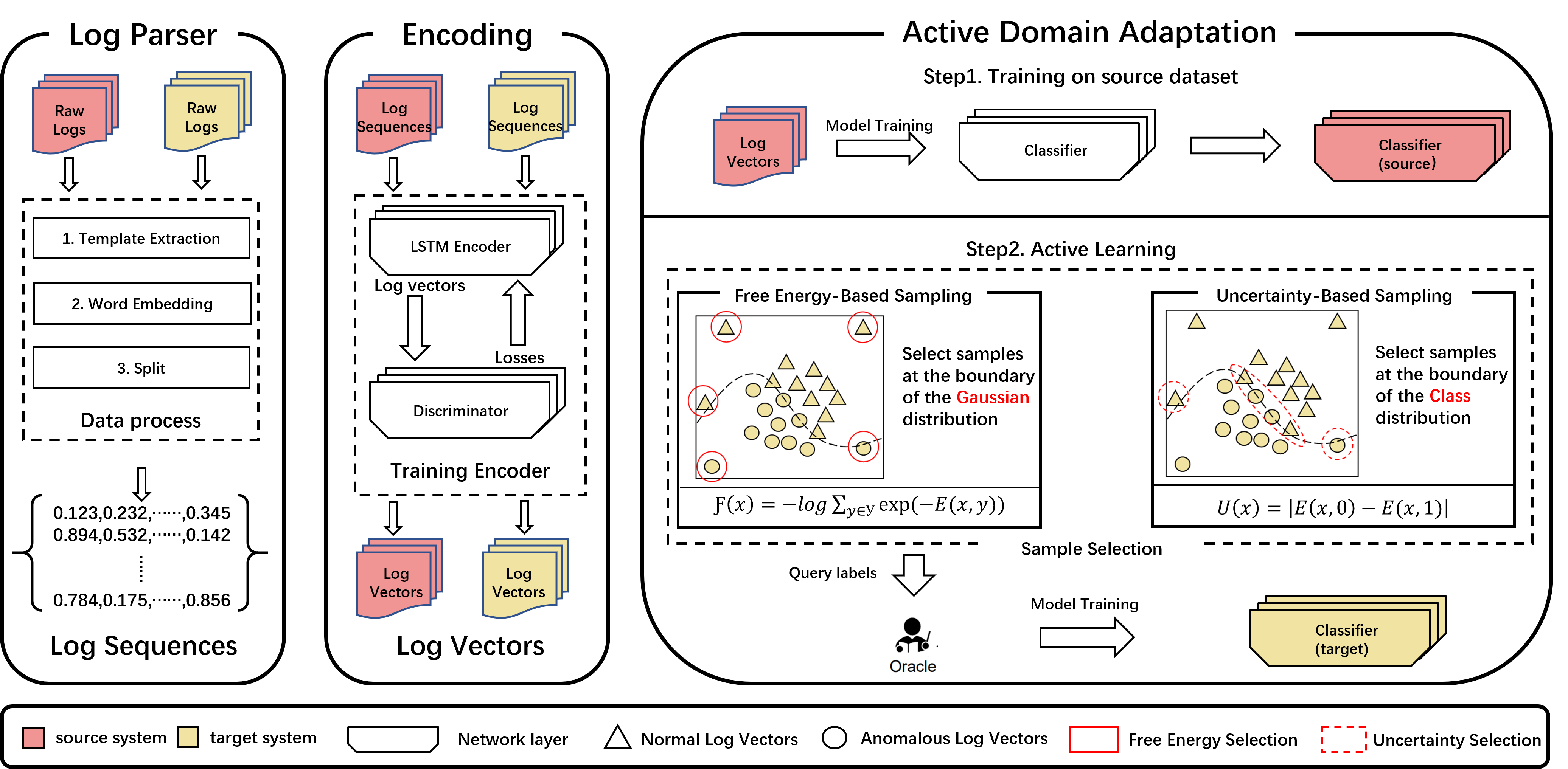
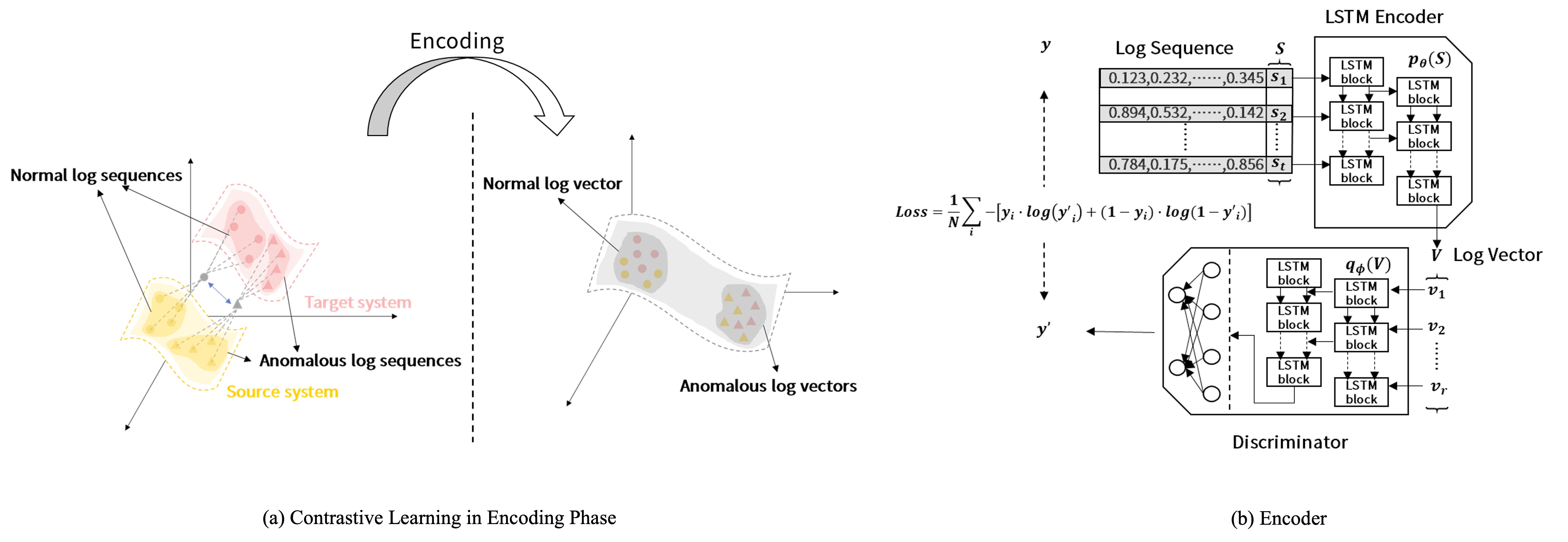
Our propose method: LogAction
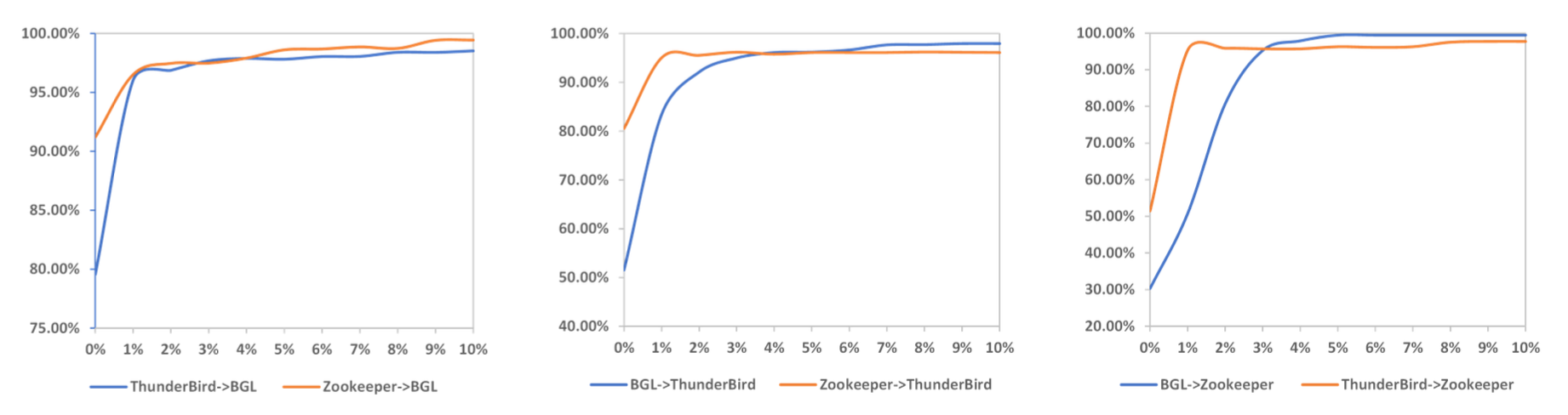
As a result, we pose an idea that transfer learning and active learning should be combined
together to solve the label lacking problem. We define this scenario as consistent
cross-system anomaly detection (CCAD), that is, leveraging the features extracted from
abundant historical labeled logs of mature systems (source systems) to build anomaly detection
models for new systems (target systems) and consistently optimize the models with online human
labels on the target systems. In this paper, we focus on the CCAD scenario and aim to build a
high performance anomaly detection model without or with very few anomalous labels. We propose
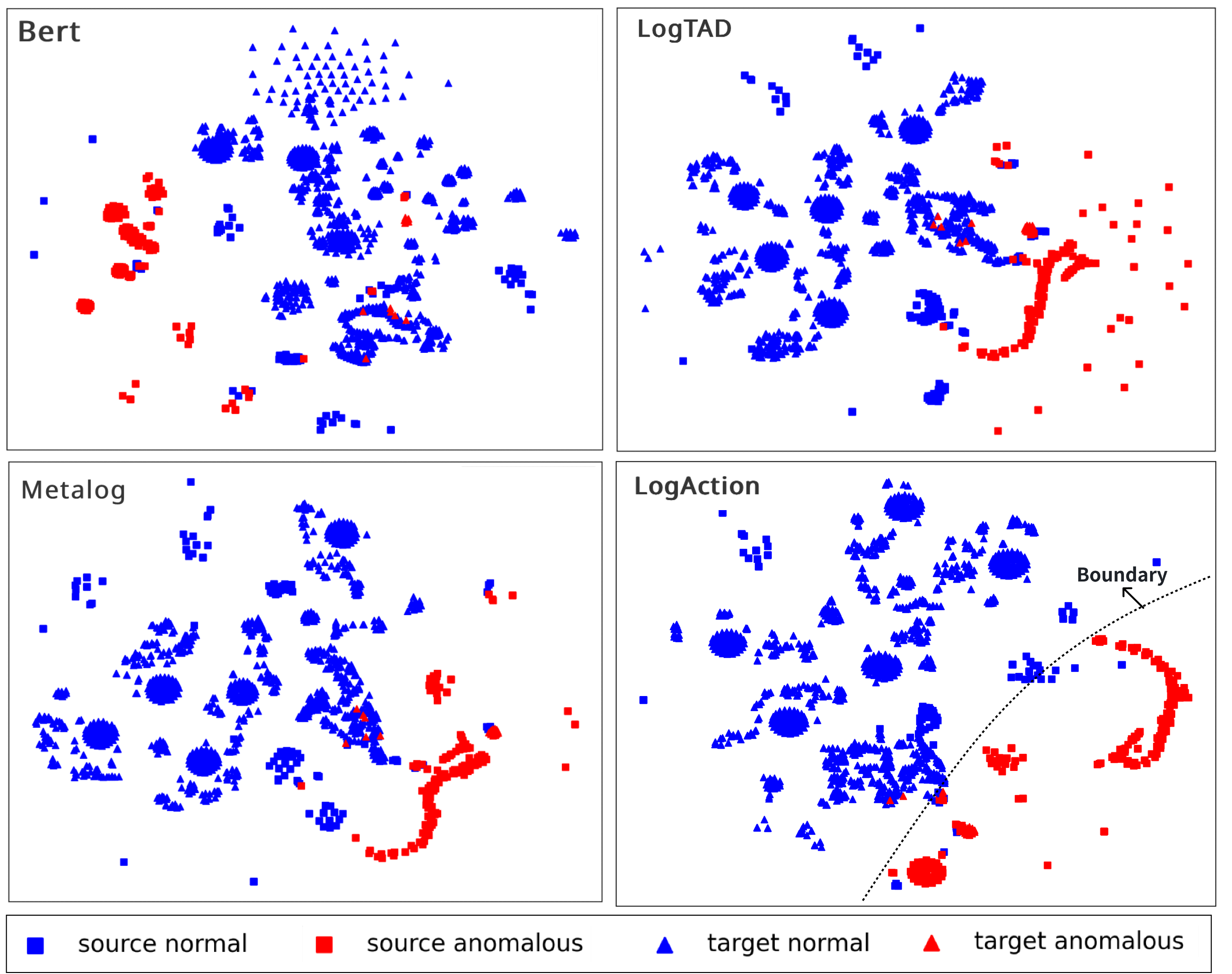
LogAction, a consistent cross-system anomaly detection model via active domain
adaptation.